Every AI call rereads the
full conversation history
Cost grows quadratically.
Query-agnostic compression keeps the wrong passages.
turn 1: [ctx]
turn 2: [ctx][ctx]
turn 3: [ctx][ctx][ctx]
⋮ O(n²)
Reads the question first.
Rewrites only what's relevant.
Reads the question
Rewrites only the relevant content — drops the rest.
1.5B · offline
Qwen2.5-1.5B + LoRA. Cents per call, no API.
Three-tier memory
Keeps multi-turn context flat — any conversation length.
ReCompress
Read the question first. Rewrite only what matters.
8.5× fewer tokens — from a 1.5B model that runs offline.
Parth Sanjay Kshirsagar · Kartikey Pandey
Zero-shot to a benchmark we never trained on.
Multi-turn stays at 184 tokens — naive reaches 1,482 by turn 12.
Paper on Zenodo · DOI 10.5281/zenodo.20786357
ReCompress
github.com/Kart-ing/ReCompress
Thank you.
Paper: 10.5281/zenodo.20786357 · Demo: demo-eight-olive-97.vercel.app
Deeper evidence — for live Q&A
benchmarks · cross-solver audit · honesty · crossover · how it's cheap · live demo
Significant where it's hardest
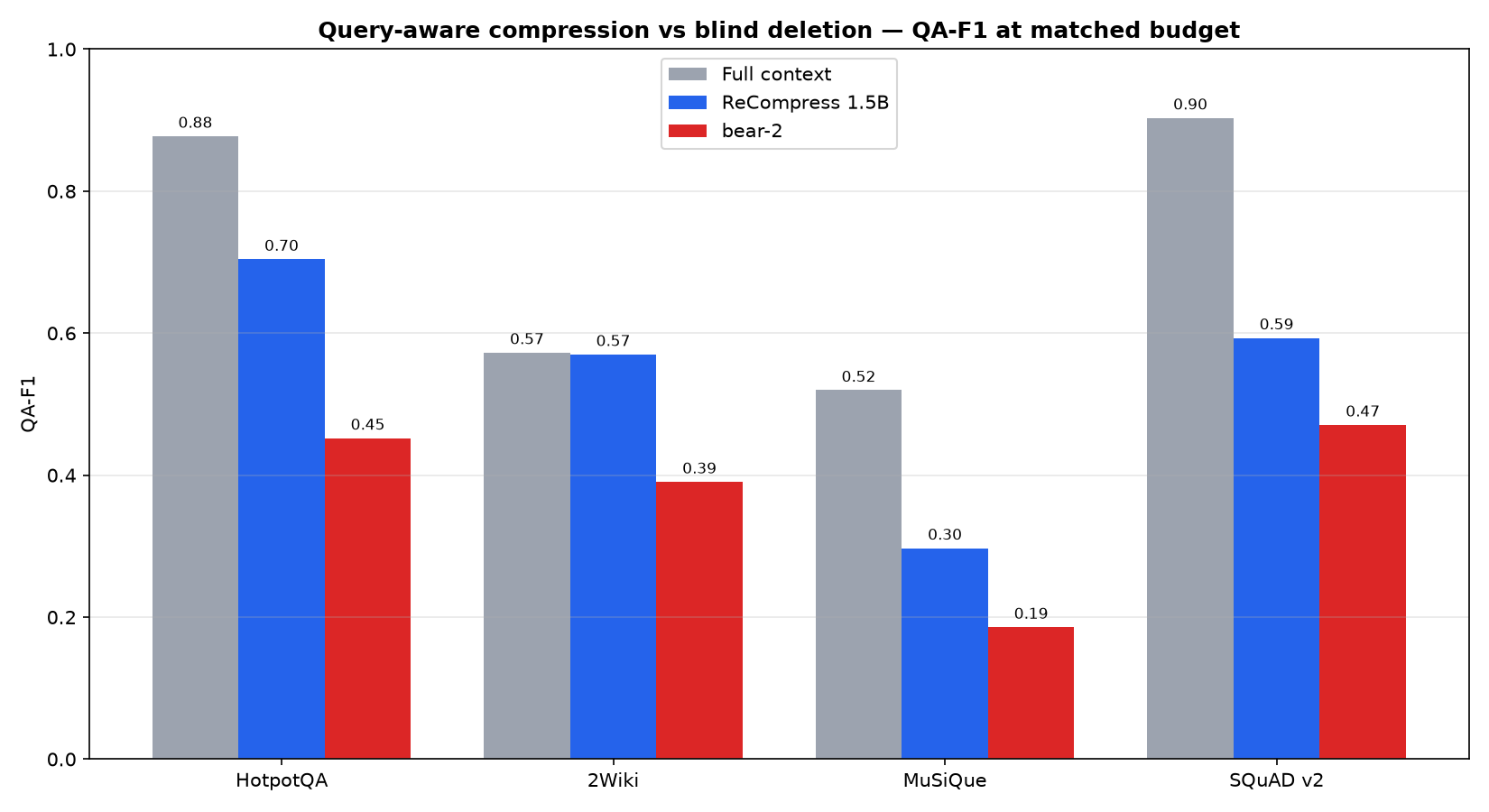
HotpotQA ✓ 2Wiki ✓ MuSiQue n.s. SQuAD n.s. — significant on multi-hop-with-distractors; honest about the rest.
The win survives an independent judge
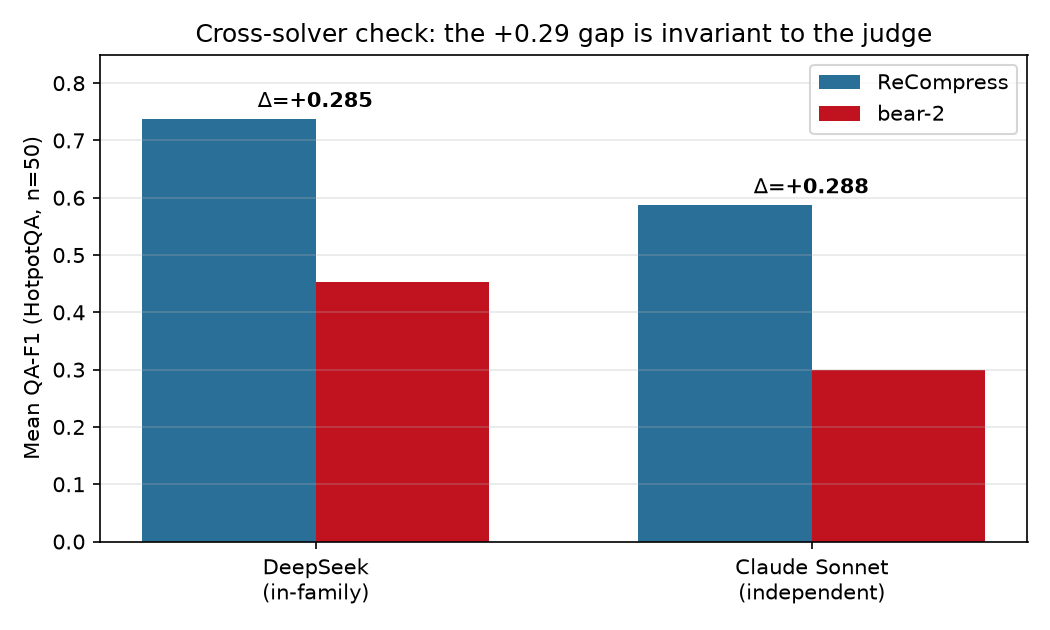
Teacher + solver were both DeepSeek. Re-scored with Claude Sonnet (independent): Δ +0.288 vs +0.285 in-family. Not a same-family artifact.
Much of the win is span-selection — measured
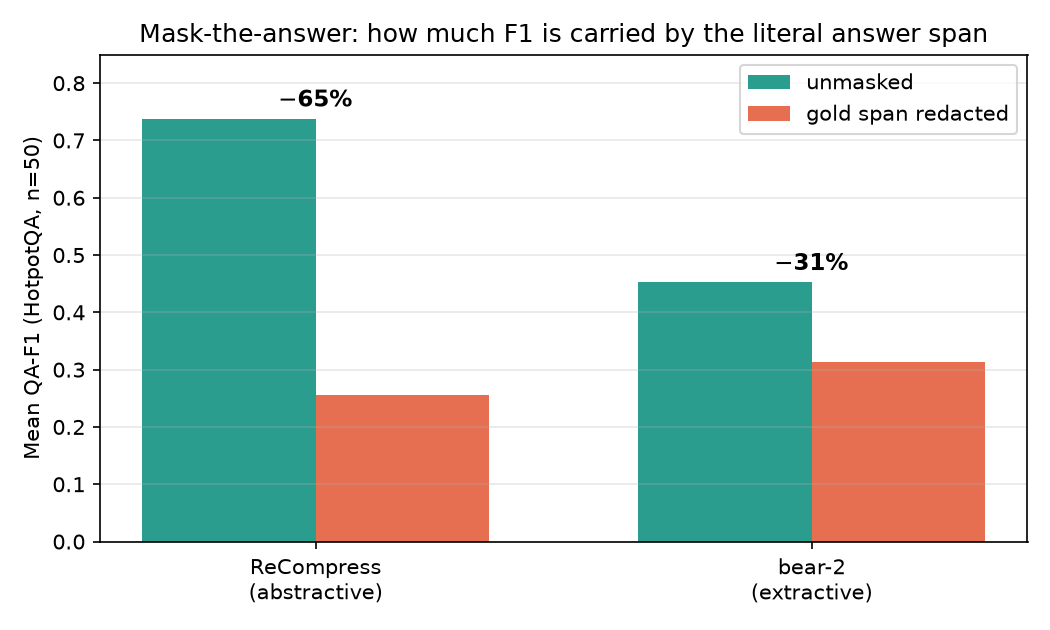
Redact the gold answer span and re-solve: our F1 drops 65% vs bear's 31%. Better selection, not better reasoning — and we report it.
Flat context — after cutting our own dead weight
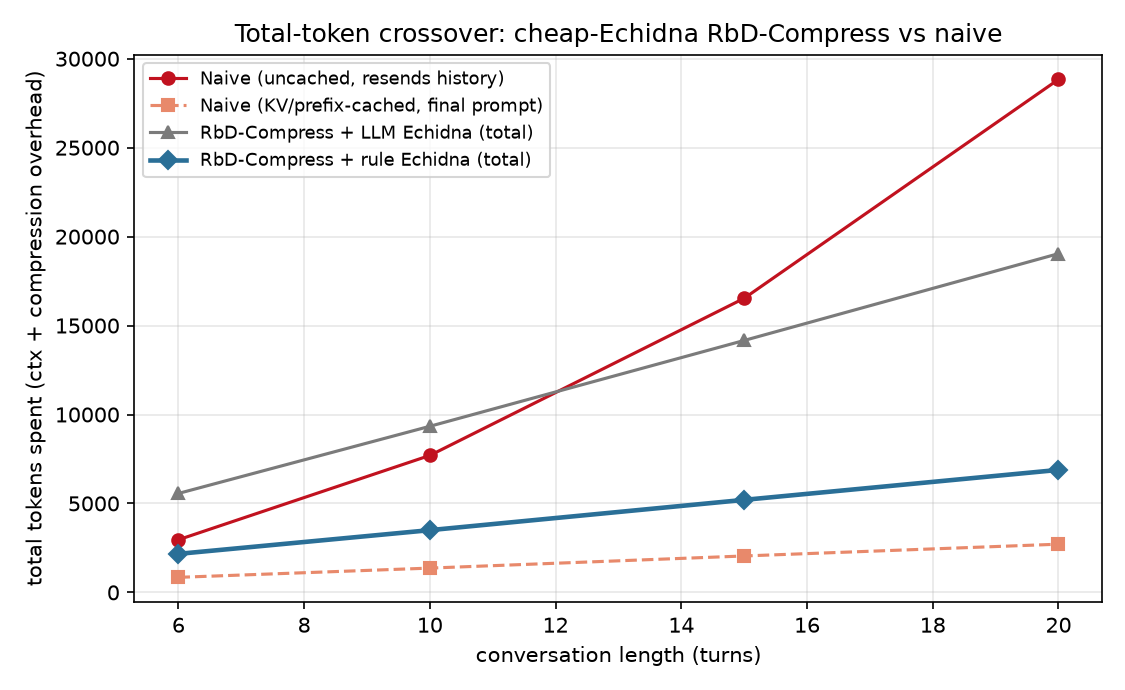
Our LLM checkpoint-trigger was 98% useless; a free rule made it 4.2× cheaper than uncached naive by 20 turns. (Honest: never beats a KV-cached agent on raw tokens.)
Three attempts: wash → overfit → win
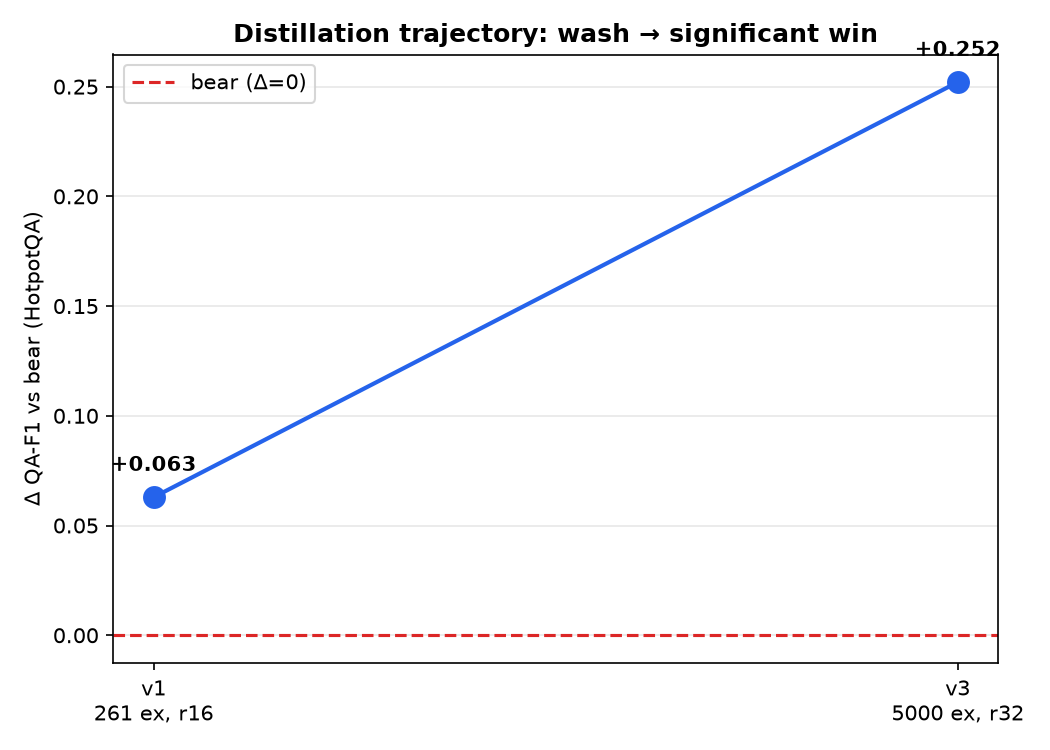
v1 under-data → v2 overfit → v3 significant. All three reported. The 1.5B recovers ~64% of the frontier teacher's margin, offline.
→ Switch to the interactive demo
cross-solver toggle · crossover slider · redact the answer live
live site embedded — or open demo-eight-olive-97.vercel.app full-screen
What we did not prove
- Significant on 2 of 4 benchmarks — MuSiQue & SQuAD are directional (n=50).
- Much of the F1 is the answer span itself (mask test) — selection, not reasoning.
- Multi-turn beats uncached naive only; a KV-cached agent wins on raw tokens.
- The student is autoregressive — ~1.8× bear's latency (for 9.4× fewer tokens).
Everything's open
ReCompress · The Token Company Compression Challenge · UC Berkeley AI Hackathon 2026